ConcurrentHashMap如何实现的
Jdk1.7的ConcurrentHashMap
jdk1.7中采用Segment + HashEntry的方式进行实现,结构如下:
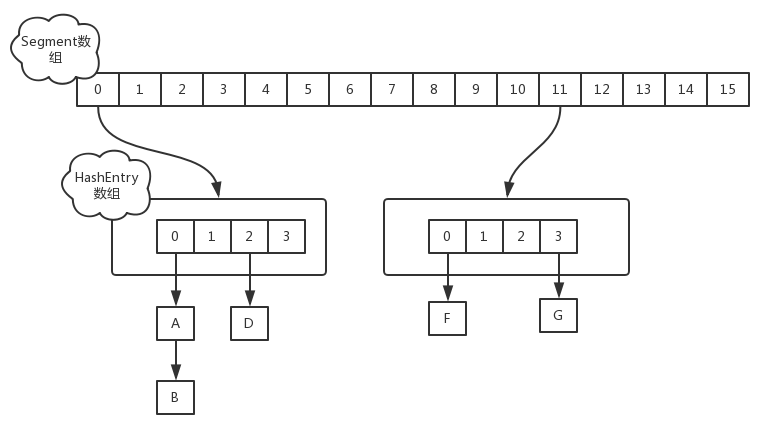
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样
1 | int sshift = 0; |
如上所示,因为ssize用位于运算来计算(ssize <<=1),所以Segment的大小取值都是以2的N次方,无关concurrencyLevel的取值,当然concurrencyLevel最大只能用16位的二进制来表示,即65536,换句话说,Segment的大小最多65536个,没有指定concurrencyLevel元素初始化,Segment的大小ssize默认为16
每一个Segment元素下的HashEntry的初始化也是按照位于运算来计算,用cap来表示,如下所示
1 | int cap = 1; |
如上所示,HashEntry大小的计算也是2的N次方(cap <<=1), cap的初始值为1,所以HashEntry最小的容量为2
put操作
对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置
从上Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒
Jdk1.8 ConcurrentHashMap
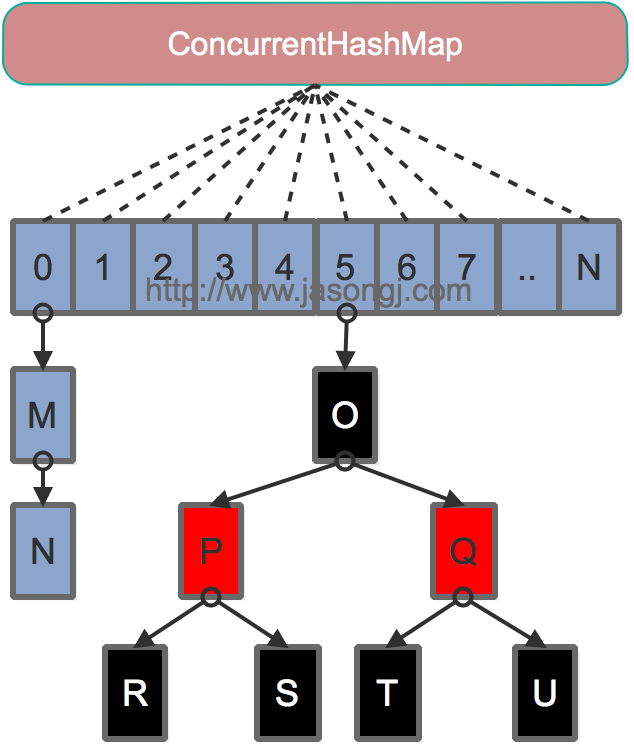
Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))。其数据结构如下图所示
put操作
get操作
1 |