面试-Kafka专题
使用Kafka时会遇到的问题
- Kafka速度很快的原因
- 如何保证消息不丢失
- Consumer重复消费怎么处理
- 如何保证消息的有序性
TODO: 待增加问题
- Offset怎么保存
- 数据倾斜怎么处理
- 一个Topic分配多少个Partition合适以及修改Partition的限制有哪些
Kafka速度很快的原因
- 磁盘的顺序读写
- 使用操作系统的Page Cache,而不是jvm内存,这样能极大加快读写速度。避免Object对象比在Linux对象更大的消耗,避免jvm数据增多GC变慢的问题
- 零拷贝,Page Cache 结合 sendfile 方法,避免拷贝到用户态内存操作,Kafka消费端的性能也大幅提升。这也是为什么有时候消费端在不断消费数据时,我们并没有看到磁盘io比较高,此刻正是操作系统缓存在提供数据。
- 批量读写,批量压缩:把所有消息都变成一个批量文件,并且执行合理的批量压缩,减少网络IO消耗
如何保证消息不丢失
消息发布的可靠性
Producer向Topic发送消息,此时网络存在异常,producer无法得知broker是否接收到该消息,网络异常可能有两种情况:
- 在消息传递过程中出现了网络出错
- 在broker已经接受到了消息,返回ack给producer的过程中网络存异常
此时可以通过producer重发消息,保证at least once
0.11.0的版本通过给每个producer一个唯一ID,并且在每个消息生成一个版本号,以对消息去重,以达到producer端的exactly once
Kafka存在如下概念来保证producer端消息的可靠性
TOPIC和日志
TOPIC指的是一个订阅主题,是数据被发布的地方,可以被多个消费者订阅
对于每个主题,kafka集群都维护了一个分区日志,如下所示
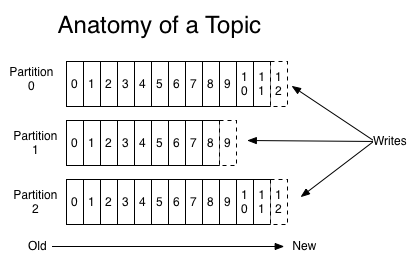
每个分区都是有序的,不可变的记录集,并且不断追加到结构化的commit log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset,offset用来唯一的标识分区中每一条记录。
消费者、消费组、消息有序性
消费者使用一个 消费组 名称来进行标识,发布到topic中的每条记录被分配给订阅消费组中的一个消费者实例.消费者实例可以分布在多个进程中或者多个机器上。
如果所有的消费者实例在同一消费组中,消息记录会负载平衡到每一个消费者实例.
如果所有的消费者实例在不同的消费组中,每条消息记录会广播到所有的消费者进程.
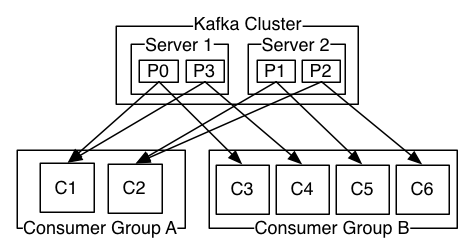
如图,这个 Kafka 集群有两台 server 的,四个分区(p0-p3)和两个消费者组。消费组A有两个消费者,消费组B有四个消费者。
通常情况下,每个 topic 都会有一些消费组,一个消费组对应一个”逻辑订阅者”。一个消费组由许多消费者实例组成,便于扩展和容错。这就是发布和订阅的概念,只不过订阅者是一组消费者而不是单个的进程。
在Kafka中实现消费的方式是将日志中的分区划分到每一个消费者实例上,以便在任何时间,每个实例都是分区唯一的消费者。维护消费组中的消费关系由Kafka协议动态处理。如果新的实例加入组,他们将从组中其他成员处接管一些 partition 分区;如果一个实例消失,拥有的分区将被分发到剩余的实例。
Kafka 只保证分区内的记录是有序的,而不保证主题中不同分区的顺序。每个 partition 分区按照key值排序足以满足大多数应用程序的需求。但如果你需要总记录在所有记录的上面,可使用仅有一个分区的主题来实现,这意味着每个消费者组只有一个消费者进程。
分布式、分区
日志的分区partition分布在kafka集群的服务器上,每个服务器在处理数据和请求时,共享这些分区,每个分区都会在已配置的服务器上进行备份,以确保容错性。
每个分区都一个server作为leader,0个或者多个server作为follower,leader server处理一切对分区的读写请求,而follower只处理被动同步leader上的数据。
ACK和副本数
副本数保证数据高可用,ACK保证Producer接受消息策略
acks=0 ,则 producer 不会等待服务器的反馈。该方式效率最高但存在消息丢失风险
acks=1 ,leader接受到消息返回确认后,就被认为消息发布成功。但此时leader宕机存在消息丢失风险
acks=-1 ,消息在所有副本都返回成功之后才被认为消息写入成功,此种方式性能比较差,但稳定性时最高的
消息接收的可靠性
暂时不支持,只能使用事务且手动提交offset方式来实现
Consumer重复消费怎么处理
问题背景
笔者基于java做了一个动态添加topic,并落地数据到Hbase的功能,其他同事在复用消费topic代码做实时统计时,出现重复消费,导致统计结果不准的现象,因为写入数据到Hbase是幂等的,重复消费所以未出现问题,但是重复消费会影响到统计结果
问题原因
使用Kafka时,禁止offset自动提交,消费者每次poll的数据业务处理时间超过kafka的max.poll.interval.ms,默认是300秒,导致kafka的broker认为consumer挂掉,触发kafka进行rebalance动作,导致重新消费
解决方式
一般消费方式如下:
1 | consumer.subscribe(topicName,rebalance) |
上述消费方式都会存在处理消息时长超过max.poll.interval.ms配置值风险,导致rebalance,所以最根本的解决方式,就是避免kafka进行rebalance动作,消费代码可使用如下方式
1 | final List<TopicPartition> newPartitionAssignments = |
主要思想是consumer指定消费topic的对应的分区,并从指定offset进行消费,来避免kafka的rebalance动作,引起重复消费,当然这会增加消费逻辑的复杂度,需考虑很多异常情况,如consumer实例下线怎么处理,新增consumer实例,超过topic分区数怎么处理等等,可参照spark structure streaming,flink消费kafka源码实现
参考https://www.jianshu.com/p/c358a78bc92c
Kafka在分布式情况下如何保证消息的有序性
同一个partition消息是有序的
Kafka 中发送1条消息的时候,可以指定(topic, partition, key) 3个参数
指定partition参数,则发往同一个partition的消息是有序的
指定key,具有同一个key的所有消息都会发送到一个partiton,也能够保证局部有序