概念-Java内存模型
2.垃圾收集算法
基于分代收集理论,可以分为年轻代、年老代两类收集算法。
年轻代:标记复制
年老代:标记整理
标记清除
其中标记清除算法是最基础的算法,后续算法都是基于标记清楚算法改进得到的
标记清除算法缺点:
- 执行效率不稳定,当年轻代有大量回收对象时候,需要执行大量标记清除动作,而标记动作通常是需要stop the world的,所以可能存在性能问题
- 内存碎片问题
标记复制
标记复制是将存活对象复制到两个Eden区的其中一个,然后回收剩下内存里的所有对象
年轻代特点是”朝生夕死”,需要复制对象数量少,所以使用标记复制进行垃圾回收效率高
一个Survivor区,两个Eden区,比例为8:1:1
- 执行第一次垃圾回收时候,将存活对象放到某个Enden区,剩下的Survivor和Eden执行回收操作
- 执行第二次垃圾回收时候,将存活对象copy到另一个Enden区,剩下的Survivor和Eden执行回收操作
标记整理
年老代特点是垃圾回收比较少,标记整理算法是年老代算法。老年代如果使用标记复制算法需要复制很多对象,效率比较低
垃圾回收器
年轻代回收器:
- Serial收集器 使用标记-复制的单线程垃圾回收器
- ParNew收集器 使用标记-复制的多线程垃圾回收器
- Parallel Scavenge收集器 和parnew区别:控制吞吐量
年老代回收器:
- Serial Old收集器 使用标记-整理算法单线程垃圾回收器
- Parallel Old收集器 使用标记-整理算法多线程垃圾回收器
- CMS收集器
全年龄收集器:G1
CMS回收器
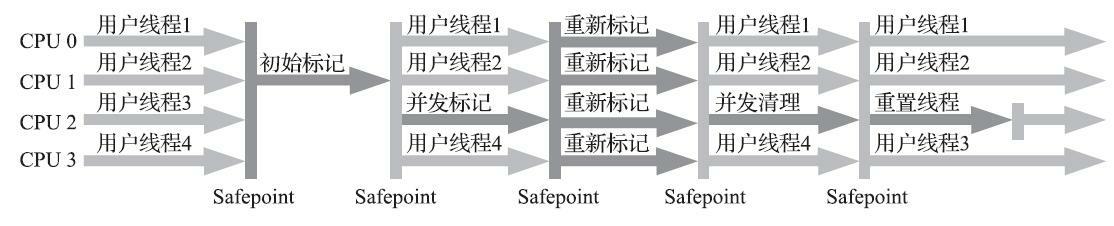
CMS是年老代回收器
- 初始标记(CM S initial mark) 单线程,会stop the world
- 并发标记(CM S concurrent mark)
- 重新标记(CM S remark) 多线程,会stop the world
- 并发清除(CM S concurrent sweep)
G1回收器
G1是基于分代理论设计的,可以同时在年轻代年老代使用。
G1将Java堆内存分成数个相等大小的区域(Region),每一个Region都可以根据需要,扮演新生代的Eden空间、Survivor空间,或者老年代空间。收集器能够对扮演不同角色的Region采用不同的策略去处理,这样无论是新创建的对象还是已经存活了一段时间、熬过多次收集的旧对象都能获取很好的收集效果。
Region还有一种是专门存储大对象的Region,G1认为只要大小超过了一个Region容量一半的对象即可判定为大对象。而对于那些超过了整个Region容量的超级大对象,将会被存放在N个连续的Humongous Region之中,G1的大多数行为都把Humongous Region作为老年代的一部分来进行看待
如果我们不去计算用户线程运行过程中的动作(如使用写屏障维护记忆集的操作),G1收集器的
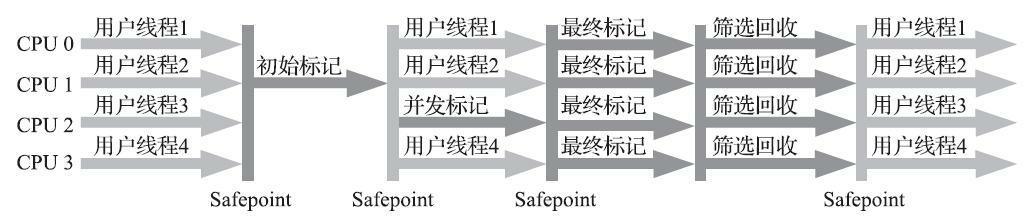
运作过程大致可划分为以下四个步骤:
- 初始标记(Initial M arking):仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAM S
指针的值,让下一阶段用户线程并发运行时,能正确地在可用的Region中分配新对象。这个阶段需要
停顿线程,但耗时很短,而且是借用进行M inor GC的时候同步完成的,所以G1收集器在这个阶段实际
并没有额外的停顿。 - 并发标记(Concurrent M arking):从GC Root开始对堆中对象进行可达性分析,递归扫描整个堆
里的对象图,找出要回收的对象,这阶段耗时较长,但可与用户程序并发执行。当对象图扫描完成以
后,还要重新处理SATB记录下的在并发时有引用变动的对象。 - 最终标记(Final M arking):对用户线程做另一个短暂的暂停,用于处理并发阶段结束后仍遗留
下来的最后那少量的SATB记录。 - 筛选回收(Live Data Counting and Evacuation):负责更新Region的统计数据,对各个Region的回
收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,可以自由选择任意多个Region
构成回收集,然后把决定回收的那一部分Region的存活对象复制到空的Region中,再清理掉整个旧
Region的全部空间。这里的操作涉及存活对象的移动,是必须暂停用户线程,由多条收集器线程并行
完成的。