2023-06-05
零拷贝传统的IO存在什么问题?为什么引入零拷贝的?如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
代码通常如下,一般会需要两个系...
Read More
2023-05-09
补充队列满时候的丢弃策略
DiscardPolicy:不处理,直接丢弃掉;
AbortPolicy:直接抛出 RejectedExecutionException 异常,这是默认的拒绝策略;
DiscardOldestPolicy:丢弃最老的任务,并执行当前任务;
CallerRunsPolicy:由调用线程本身运行任务,以减缓提交速度,会阻塞主线程;
...
Read More
2023-05-07
Bean的生命周期:
获取Bean的定义
xml和annotion获取初始Bean定义
经BeanFactoryPostProcessors处理获取完整定义
反射得到Bean对象
初始化Bean(赋值Bean属性)
初始化普通Bean对象
初始化aware接口对象
使用Bean
销毁Bean
Read More
2023-05-01
123456789wget http://repo.mysql.com/mysql-apt-config_0.8.10-1_all.debsudo dpkg -i mysql-apt-config_0.8.10-1_all.debsudo dpkg-reconfigure mysql-apt-configsudo apt updatesudo apt-cac...
Read More
2023-04-27
元注解@Target 最常用的元注解是@Target。使用@Target可以定义Annotation能够被应用于源码的哪些位置:
类或接口:ElementType.TYPE;
字段:ElementType.FIELD;
方法:ElementType.METHOD;
构造方法:ElementType.CONSTRUCTOR;
方法参数:ElementType.PARAMETER。
例如,定义注解@Report可用在方法上,我们必须添加一个@Target(ElementType.METHOD):
如何自定义注解 第一步,用@interface定义注解:
1 2 3 public @interface Report {}
Read More
2023-04-27
一. Java虚拟机内存区域1. 运行时数据区
2. 程序计数器(Program Counter Register)
1、程序计数器是线程内(每个线程都有唯一的、封闭的)一小块内存区域
2、计数器指定的是当前虚拟机执行指令的地址
3、当虚拟机执行的是Native方法时,计数器值为空(Undefined),此内存区域是唯一一个在Java虚拟机规范中没有规...
Read More
2023-04-27
使用ReentrantLock比直接使用synchronized更安全,可以替代synchronized进行线程同步。
但是,synchronized可以配合wait和notify实现线程在条件不满足时等待,条件满足时唤醒,用ReentrantLock我们怎么编写wait和notify的功能呢?
答案是使用Condition对象来实现wait和notify的...
Read More
2023-04-24
Java对象的创建创建java对象大概归纳为以下步骤
类加载检查
为新生对象分配内存
对类进行初始化操作
1.类加载检查当Java虚拟机遇到一条字节码new指令时,首先将去检查这个指令的参数是否能在常量池中定位到一个类的符号引用,并且检查这个符号引用代表的类是否已被加载、解析和初始化过。如果没有,那必须先执行相应的类加载过程
2.为新生对象分配内存指针碰...
Read More
2023-04-24
-Xmx10m设置虚拟机最大堆内存
-Xms10设置虚拟机初始堆内存,可与-Xmx相等避免每次GC重新内存分配
-Xmn10m设置堆年轻代大小
-Xss1m设置栈内存
#出现 OOME 时生成堆 dump:-XX:+HeapDumpOnOutOfMemoryError#生成堆文件地址:-XX:HeapDumpPath=/temp/...
Read More
2023-04-24
1. 内存模型
2. 内存间的交互操作2.1. 定义操作
lock(锁定):作用于主内存的变量,它把一个变量标识为一条线程独占的状态.
unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定.
read(读取):作用于主内存的变量,它把一个变量的值从主内存传输到线程的工作内存中,以便随后的load动作...
Read More
2023-04-24
1. JAVA与线程1.1 线程的实现
实现方式:使用内核线程实现、 使用用户线程实现和使用用户线程加轻量级进程混合实现.
JDK1.2之前是基于用户线程实现的,JDK1.2及以后是基于操作系统原生线程模型实现的.
1.2 Java线程调度
线程调度是指系统为线程分配处理器使用权的过程,主要调度方式有两种,分别是协同式线程调度(Cooperative Th...
Read More
2023-04-24
IoC、Bean、依赖注入IoC是控制反转,含义是把创建对象的操作交给Spring执行
把创建好的对象放到IoC容器,放到IoC容器的对象叫做Bean。放入IoC容器之前的赋值这个动作叫做依赖注入
AOP指的是在执行某个方法这个时刻,会先执行一些预定义好的操作。这个执行过程叫做切面。比较常见的例子是打印日志、Spring的事务
Bean创建的过程有一个步骤可...
Read More
2023-04-24
CyclicBarrier是java提供的同步辅助类。一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point),才得以继续执行。阻塞子线程,当阻塞数量到达定义的参与线程数后,才可继续向下执行。
1234567891011121314151617181920212223public class Barrier...
Read More
2023-04-24
CountDownLatch 是多线程控制的一种工具,它被称为 门阀、 计数器或者 闭锁。这个工具经常用来用来协调多个线程之间的同步,或者说起到线程之间的通信(而不是用作互斥的作用)。下面我们就来一起认识一下 CountDownLatch
认识 CountDownLatchCountDownLatch 能够使一个线程在等待另外一些线程完成各自工作之后,再继...
Read More
2023-04-24
从Java 5开始,引入了一个高级的处理并发的java.util.concurrent包,它提供了大量更高级的并发功能,能大大简化多线程程序的编写。
我们知道Java语言直接提供了synchronized关键字用于加锁,但这种锁一是很重,二是获取时必须一直等待,没有额外的尝试机制。
java.util.concurrent.locks包提供的Reentran...
Read More
2023-04-24
如果你在之前的文章中我们已经了解过了 java中的管程sychronized实现原理,那么再来看AbstractQueuedSynchronizer的实现就会非常简单了,虽然使用的加锁技术有不同之处,但是他们都是基于同样的理念去实现的.
打开ReentrantLock 的源码你会发现,ReentrantLock 的所有操作都是基于Sycn对象去操作的,而S...
Read More
2023-04-24
前面我们讲了各种锁的实现,本质上锁的目的是保护一种受限资源,保证同一时刻只有一个线程能访问(ReentrantLock),或者只有一个线程能写入(ReadWriteLock)。
还有一种受限资源,它需要保证同一时刻最多有N个线程能访问,比如同一时刻最多创建100个数据库连接,最多允许10个用户下载等。
这种限制数量的锁,如果用Lock数组来实现,就太麻烦了...
Read More
2023-04-24
可用的State BackendFlink提供三种开箱即用的State Backend:
HashMapStateBackend
EmbeddedRocksDBStateBackend
HashMapStateBackendHashMapStateBackend在java堆上保存数据,健值对的状态和windows函数使用hashtable存储值或者触发...
Read More
2023-04-15
2.垃圾收集算法基于分代收集理论,可以分为年轻代、年老代两类收集算法。
年轻代:标记复制
年老代:标记整理
标记清除其中标记清除算法是最基础的算法,后续算法都是基于标记清楚算法改进得到的
标记清除算法缺点:
执行效率不稳定,当年轻代有大量回收对象时候,需要执行大量标记清除动作,而标记动作通常是需要stop the world的,所以可能存在性能问题
内存碎...
Read More
2021-05-31
什么是循环依赖一般场景是一个Bean A依赖Bean B,而Bean B也依赖Bean A.Bean A → Bean B → Bean A
当然我们也可以添加更多的依赖层次,比如:Bean A → Bean B → Bean C → Bean D → Bean E → Bean A
Spring发生了什么当 Spring 上下文加载所有 bean 时,它会...
Read More
2021-05-26
有些时候我们需要查看下jvm中的线程执行情况,比如,发现服务器的CPU的负载突然增
高了、出现了死锁、死循环等,我们该如何分析呢?
由于程序是正常运行的,没有任何的输出,从日志方面也看不出什么问题,所以就需要
看下jvm的内部线程的执行情况,然后再进行分析查找出原因。
用法:jstack
java线程的6种状态
初始态(NEW)
创建一个Thread对象...
Read More
2021-04-29
使用guava缓存数据源
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465package com.code.note.test;import java.util.Ha...
Read More
2021-04-14
CheckPoint数据在内存中的这个过程叫做data buffer,数据已经存储在磁盘上叫data file。
事务的日志也一样,在内存中叫log buffer,在磁盘上叫log file。
data buffer的数据定时写入到data file,这个定时执行的过程是checkpoint。
如果checkpoint失败,在恢复时候,只需要做最后一次re...
Read More
2021-04-08
题目描述Es集群中有一个节点性能很差,会导致Es整体查询变慢,当该物理节点被关闭但存在部分分片没有分配到其他节点上。
解决方案因为配置文件中被关闭的机器ip是存在的,Es存在一个探活过程,所以这些分片没有被自动迁移到其他节点。
可以通过Exclude该机器的IP来动态删除该机器,删除10.1.1.1节点命令:
12345curl -XPUT http://1...
Read More
2021-04-08
题目描述12345678910111213在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。示例 1:输入: [3,2,1,5,6,4] 和 k = 2输出: 5示例 2:输入: [3,2,3,1,2,4,5,5,6] 和 k = 4输出: 4说明:你可以假设 k 总是有效的,且 1 ...
Read More
2021-04-07
题目描述123456789101112131415给你一个整数数组 nums,请你将该数组升序排列。 示例 1:输入:nums = [5,2,3,1]输出:[1,2,3,5]示例 2:输入:nums = [5,1,1,2,0,0]输出:[0,0,1,1,2,5]
堆排序的性质
堆是一颗满二叉树
子节点和父节点下标关系:leftChild = pa...
Read More
2021-04-02
快速排序1以第一个数字6作为基数,使用双指针i,j进行双向遍历:
1、i从左往右寻找第一位大于基数(6)的数字,j从右往左寻找第一位小于基数(6)的数字;
2、找到后将两个数字进行交换。继续循环交换直到i>=j结束循环;
3、最终指针i=j,此时交换基数和i(j)指向的数字即可将数组划分为小于基数(6)/基数(6)&#x...
Read More
2021-03-24
Java内存模型被提出的背景Java内存模型被提出主要是为解决如下问题
硬件效率问题
计算机内存比CPU慢很多,所以需要在CPU和主存之间加寄存器和高速缓存。
缓存一致性问题
代码指令重排导致多线程执行的“乱序问题”
什么是Java内存模型Java 虚拟机规范中试图定义一种 Java 内存模型(Java Memory Model,简称 JMM)来屏蔽掉各...
Read More
2021-03-08
这个题得用后序遍历,用前序遍历删不干净
12345678910111213141516public TreeNode pruneTree(TreeNode root) { if (root == null) { return null; } root.left...
Read More
2021-03-08
题目分析
前序遍历的特点是preorder[0]是根节点
中序遍历的特点是跟节点左边是左子树,跟节点右边是右子树
123456789101112131415161718192021222324252627282930313233343536373839public class Test { public TreeNode buildTr...
Read More
2021-03-05
使用vim查询spend=14435的命令是,
/spend=[1-9]\{5,5\}
其中[1-9]表示任意一个1~9的数字
\{5,5\}上面的数字表示出现了5次,即匹配14435
Read More
2021-03-05
CMS垃圾回收CMS垃圾回收收集所有代。它会使用最小的资源来进行大多数垃圾回收工作,通常低停顿并发收集器不会复制或者压缩活动的对象。在不移动活动对象的情况下完成垃圾回收。如果内存碎片导致无法正常分配内存,请分配更大的堆内存。
CMS在年老带执行垃圾收集会氛围以下几个阶段
Phase
Description
(1) Initial Mark (St...
Read More
2021-03-05
G1垃圾回收G1(Garbage-First) 收集器是为服务器准备的垃圾回收器,是为很多核大内存服务器准备的垃圾回收器。它在达到高吞吐量时满足了GC停顿时间可预测这样的一个目标。在Oracle JDK 7 update4 及以后的版本被支持。G1收集器是为如下程序设计:
垃圾收集于应用线程之间是并发的
紧凑的自由空间且没有较长的GC停顿时间
需要更可以预...
Read More
2021-03-05
G1收集器采用了另一种分配堆的方法。 后面的图片逐步检查了G1系统。
G1堆结构G1堆事一个内存区域被切分为多个相同大小的区域(regions)
区域大小是在jvm一启动就被选择的。JVM通常会生成两千个区域,每个区域大小相同,在1到32MB之间
G1堆分配事实上,这些区域被映射成Eden、Survivor和年老代
图片中的颜色显示了哪个区域与哪个角色相...
Read More
2021-03-05
聊聊Spring
控制反转思想IOC
依赖注入AOP
bean的生命周期
循环依赖
三级缓存
FactoryBean和BeanFactory区别
ApplicationContxt和BeanFactory区别
Spring中的设计模式
Read More
2021-03-03
B树B树和平衡二叉树稍有不同的是B树属于多叉树又名平衡多路查找树(查找路径不只两个),数据库索引技术里大量使用者B树和B+树的数据结构,让我们来看看他有什么特点
排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多...
Read More
2021-03-03
hash索引和B+Tree索引区别
hash索引只适合等值查询,无法进行范围查询
存在大量键值重复时候,hash索引效率很低
hash索引无法利用索引进行排序
hash索引无法利用联合索引做前缀匹配原则
B+Tree叶子节点能存储哪些东西可以存储整行数据或者是主键索引值,当存储整行数据时候为主键索引,存储主键索引时候是非主键索引。非主键索引在进行查询时候需...
Read More
2021-03-03
表结构:(有一个联合索引idx_userid_age,userId在前,age在后)
12345678CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userId` int(11) NOT NULL, `age` int(11) DEFAULT NULL, `name` var...
Read More
2021-03-03
基本数据类型枚举
数字类型:byte,short,int,long
浮点型:float,double
布尔类型:boolean
字符型:char
计算机内存的最小存储单元是字节(byte),一个字节就是一个8位二进制数,即8个bit。它的二进制表示范围从00000000~11111111,换算成十进制是0~255,换算成十六进制是00 ~ ff。其中最高位...
Read More
2021-03-03
hash索引和b+tree索引区别hash索引只能等值查询,无法进行范围查询hash索引无法索引自动排序hash索引键值重复严重效率变得很低hash索引无法使用做匹配前缀原则
B+Tree数据叶子结点数据存储B+Tree叶子节点可以存储整行的数据,也可以存储主键索引。存储整行数据表示是主键索引。存储主键索引值表示是非主键索引。非主键索引查找数据需要先找到主键...
Read More
2021-03-02
不可变的好处1. 可以缓存 hash 值
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
2. String Pool 的需要
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 Strin...
Read More
2021-03-02
题目
这个题用链表方式可以实现,但效率很低
因为是回文链表,使用快慢指针,每次循环让fast走两步,slow走一步
反转后半段链表,反转起始节点为当前slow节点
题目解答12345678910111213141516171819202122232425262728293031323334353637383940414243public class Solu...
Read More
2021-03-01
题目概述
题目解答迭代解法
3和4 :反转节点
1、2: 后移旧头节点
12345678910111213public ListNode reverseList(ListNode head) { ListNode newHead = null; while(head != null){ ListNode ...
Read More
2021-02-28
两数之和
两数之和的话需要遍历两次
条件是nums[i] + nums[j] == target
题目解答123456789101112131415161718192021222324252627package com.code.note.arrays;import java.util.Arrays;public class TwoSu...
Read More
2021-02-24
题目地址剑指 Offer 27. 二叉树的镜像题目概述
题目分析
递归结束条件:root为空返回true
递归每层做什么:前序遍历所有节点,并交换left和right节点
递归返回:当前root节点
题目解答12345678910111213141516171819202122232425262728293031/** * Definition fo...
Read More
2021-02-19
题目地址剑指 Offer 68 - II. 二叉树的最近公共祖先题目概述
题目分析
递归结束条件:返回节点为空时结束递归
根据题目可以得知p、q节点分布存在三种情况:
p q 一个在左子树 一个在右子树 那么当前节点即是最近公共祖先(即根节点root)
p q 都在左子树 (先被找到的即为最近父节点)
p q 都在右子树
递归返回:无返回
题目解答12...
Read More
2021-02-19
题目概述输入字符串转成double数字
题目分析
字符串是否为空
字符串是否包含非数字
字符串是否包含正负号
是否超过double最大值
题目解答1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575...
Read More
2021-02-19
题目概述https://leetcode-cn.com/problems/maximum-binary-tree/
题目分析
二叉树的根是数组 nums 中的最大元素(写一个函数获取当前数组中的最大index)
左子树是通过数组中 最大值左边部分 递归构造出的最大二叉树。
右子树是通过数组中 最大值右边部分 递归构造出的最大二叉树。
写一个函数用来返回
...
Read More
2021-02-17
题目地址剑指 Offer 54. 二叉搜索树的第k大节点题目概述
题目分析为什么在中序遍历时候更改cnt值?大概是因二叉搜索树的中序遍历是有序的
递归结束条件:当x节点为空时结束递归
递归每层做什么:right -> mid -> left 依次访问,在中序遍历修改cnt值,当++cnt == k时记录val并结束遍历
递归...
Read More
2021-02-14
题目地址110. 平衡二叉树题目概述
题目分析左右子树高度差大于1返回false,这个需要递归到每一层
递归结束条件:root为空返回true,左右子树高度差值大于1返回false
递归每层做什么:计算左树、右树高度
递归返回:高度值
题目解答123456789101112131415161718public boolean isBalanced(...
Read More
2021-02-14
题目地址101. 对称二叉树题目概述
题目分析递归的难点在于:找到可以递归的点 为什么很多人觉得递归一看就会,一写就废。 或者说是自己写无法写出来,关键就是你对递归理解的深不深。
对于此题: 递归的点怎么找?从拿到题的第一时间开始,思路如下:
1.怎么判断一棵树是不是对称二叉树? 答案:如果所给根节点,为空,那么是对称。如果不为空的话,当他的左子树与右子树对...
Read More
2021-02-12
题目地址617. 合并二叉树题目概述
这道题其实就是把二叉树每个节点的值相加,并放到新的二叉树节点,如果某棵树当前节点为空,他的value值是0
其实这个题主要考察的是二叉树遍历,只不过需要同时遍历两棵树,二叉树遍历代码如下:
123456789101112private Node walk(Node x) { if (x == null) ...
Read More
2021-01-27
需求背景 因为mybatis不好拼装如下sql
1 2 3 select doc_id,encourage_card_id from encourage_card_quantitative_fake_progress where (doc_id = 'a' and encourage_card_id = 'b' ) or (doc_id = 'c' and encourage_card_id = 'd' )
Read More
2021-01-27
需求背景 1.按小时、天查询不同表
2.按照特定领域、全领域按照不同字段排序
3.按照文章类型进行排序
因此条件很多,需要多个if条件判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 private List<MysqlBillboardCateTopviewDoc> getHourOrDayDocs (String cate, BillboardScheduleReq.PostType postType, BillboardScheduleReq.SortType sortType) { List<MysqlBillboardCateTopviewDoc> hourOrDayDocs; if (sortType == BillboardScheduleReq.SortType.hour) { if (Strings.isBlank(cate)) { hourOrDayDocs = mysqlBillboardCateTopviewDocHourlyService.listAllCatePostTypeHourly(postType.getValue()); } else { hourOrDayDocs = mysqlBillboardCateTopviewDocHourlyService.listTypeCatePostTypeHourly(cate, postType.getValue()); } } else { if (Strings.isBlank(cate)) { hourOrDayDocs = mysqlBillboardCateTopviewDocDailyService.listAllCatePostTypeDaily(postType.getValue()); } else { hourOrDayDocs = mysqlBillboardCateTopviewDocDailyService.listTypeCatePostTypeDaily(cate, postType.getValue()); } } return hourOrDayDocs; }
Read More
2020-11-30
Flink DataStream中union和connect都有一个共同的作用,就是将2个流或多个流合成一个流。但是两者的区别是:union连接的2个流的类型必须一致,connect连接的流可以不一致,但是可以统一处理。
具体看下面示例:
123public class ConnectOperator {}
connect可以将2个不同...
Read More
2020-11-30
原题链接:654. 最大二叉树
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
二叉树的根是数组中的最大元素。
左子树是通过数组中最大值左边部分构造出的最大二叉树。
右子树是通过数组中最大值右边部分构造出的最大二叉树。
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
Read More
2020-11-15
深度优先遍历算法(DFS) 深度优先遍历算法(Depth-First-Search),是一种用于遍历或搜索树或图的算法。这个算法会尽可能深地搜索树的分支。当节点v所在的边都一杯探寻过,搜索将回溯到发现节点v的那条边的节点。选择其中一个座位源节点并重复以上过程,整个进程反复进行,直到所有节点都被访问位置。
前序、中序、后序遍历都属于深度优先遍历算法
Read More
2020-11-05
再读完Java自定义注解(一)我们可以通过代码来实现我们自己的自定义注解
如何自定义注解 EventBean类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.code.note.annotation;import lombok.Data;@Data public class EventBean { @EventName("coding now...") private String name; @EventType(eventType = EventType.Type.MEETING) private String type; @User(id = 1, name = "testName", email = "15090552277@163.com") private String user; }
Read More
2020-11-05
元注解@Target 最常用的元注解是@Target。使用@Target可以定义Annotation能够被应用于源码的哪些位置:
类或接口:ElementType.TYPE;
字段:ElementType.FIELD;
方法:ElementType.METHOD;
构造方法:ElementType.CONSTRUCTOR;
方法参数:ElementType.PARAMETER。
例如,定义注解@Report可用在方法上,我们必须添加一个@Target(ElementType.METHOD):
如何自定义注解 第一步,用@interface定义注解:
1 2 3 public @interface Report {}
Read More
2020-11-05
二叉树需要声明一个Node节点,包含节点得值,以及左右两个子节点
Node节点代码如下
1 2 3 4 5 6 7 8 9 10 11 12 package com.code.note.tree;public class Node <T extends Comparable >{ T value; Node left; Node right; Node(T value) { this .value = value; } }
Read More
2020-11-03
Flink DataStream中union和connect都有一个共同的作用,就是将2个流或多个流合成一个流。但是两者的区别是:union连接的2个流的类型必须一致,connect连接的流可以不一致,但是可以统一处理。
具体看下面示例:
123456789101112131415161718192021222324252627282930313233343...
Read More
2020-10-20
Function函数概念 Function作为一个函数式接口,主要方法apply接受一个参数,返回一个值
举个例子123456789101112131415161718192021222324252627package com.bd.thread;import lombok.extern.slf4j.Slf4j;import java.util.functi...
Read More
2020-10-20
一个简单的例子背景在写程序时候常常有一些资源初始化方法,我们希望这些方法能够被自动调用 ,可以使用如下方式实现自动调用
代码父类代码如下:
1234567891011121314package com.bd.autocall;import lombok.extern.slf4j.Slf4j;@Slf4jpublic abstract class Super ...
Read More
2020-07-20
下载python3安装包wget -c https://www.python.org/ftp/python/3.7.3/Python-3.7.3.tgz
安装linux依赖yum install libffi-devel openssl openssl-devel sqlite-devel bzip2-devel -y
在源码安装文件中编辑文件Modules...
Read More
2020-07-11
ssh端口为22情况 在服务器端172.27.9.121搭建仓库
1.在仓库目录/tmp/myproject.git输入git init
2.允许上传代码
1 git config receive.denyCurrentBranch ignore
Read More
2020-07-11
使用Kafka时会遇到的问题
Kafka速度很快的原因
如何保证消息不丢失
Consumer重复消费怎么处理
如何保证消息的有序性
Read More
2020-07-10
在/etc/profile中增加如下内容
1234567891011export JAVA_HOME=/usr/local/java/jdk1.8.0_191export PYSPARK_PYTHON=/usr/python3/bin/python3export PYSPARK_DRIVER_PYTHON=/usr/python3/bin...
Read More
2020-07-10
12345678910111213141516171819$ network-manager.nmcli connection edit type 802-11-wirelessnmcli> goto 802-11-wirelessnmcli 802-11-wireless> set ssid <your_ssid>nmcli 802...
Read More
2020-07-07
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
Read More
2020-07-06
LinkedMap为什么是有序MapLinkedMap底层存储是数组,初始大小为16
LinkedMap返回的set是有序的,是因为KeySet中的iterator是有序的
LinkedMap在put时候,使用for循环,且起始位置用hashIndex算出来的
1234567891011121314151617181920protected int hash...
Read More
2020-07-06
常见OOM类型 堆溢出 错误信息:java.lang.OutOfMemoryError: Java heap space
Java堆用于存储对象实例,只要不断地创建对象,并且保证GC Roots到对象之间有可达路径来避免垃圾回收机制清除这些对象,那么在对象数量到达最大堆的容量限制后就会产生内存溢出异常。
Read More
2020-07-06
Spark部署模式
standalone模式,开启7077端口提供服务
spark on yarn模式 :
client 模式, driver运行在客户端,调试用
cluster模式, 分布式运行,driver运行在集群子节点
Read More
2020-07-03
什么是窗口 Windows是处理流试计算的核心。 Windows将流分成有限个大小的“存储桶”,我们可以在“存储桶”上应用计算。
窗口类型 Tumbling Window 翻滚窗口,无数据重叠
滚动窗口分配器将每个元素分配给指定窗口大小的窗口。 滚动窗口具有固定的大小,并且不重叠。 例如,如果您指定大小为5分钟的翻滚窗口,则将评估当前窗口,并且每五分钟将启动一个新窗口,如下图所示。
Read More
2020-06-30
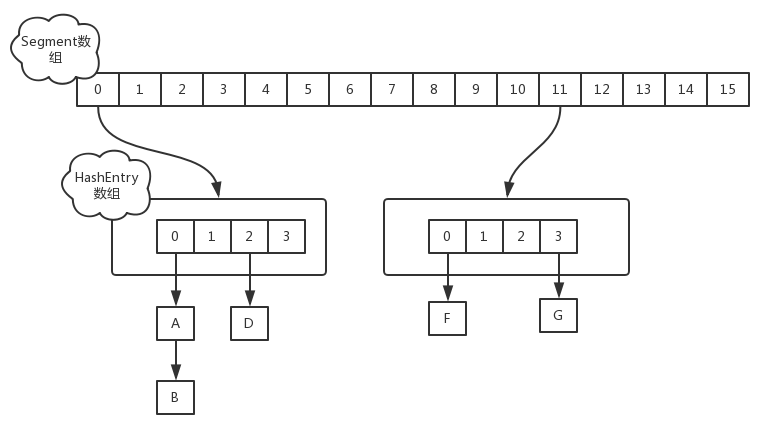
Jdk1.7的ConcurrentHashMap jdk1.7中采用Segment + HashEntry的方式进行实现,结构如下:
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,也就是上面的提到的锁分离技术,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样
1 2 3 4 5 6 int sshift = 0 ;int ssize = 1 ;while (ssize < concurrencyLevel) { ++sshift; ssize <<= 1 ; }
如上所示,因为ssize用位于运算来计算(ssize <<=1),所以Segment的大小取值都是以2的N次方,无关concurrencyLevel的取值,当然concurrencyLevel最大只能用16位的二进制来表示,即65536,换句话说,Segment的大小最多65536个,没有指定concurrencyLevel元素初始化,Segment的大小ssize默认为16
每一个Segment元素下的HashEntry的初始化也是按照位于运算来计算,用cap来表示,如下所示
1 2 3 int cap = 1 ;while (cap < c) cap <<= 1 ;
如上所示,HashEntry大小的计算也是2的N次方(cap <<=1), cap的初始值为1,所以HashEntry最小的容量为2
put操作 对于ConcurrentHashMap的数据插入,这里要进行两次Hash去定位数据的存储位置
从上Segment的继承体系可以看出,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒
Jdk1.8 ConcurrentHashMap Java 8为进一步提高并发性,摒弃了分段锁的方案,而是直接使用一个大的数组。同时为了提高哈希碰撞下的寻址性能,Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(long(N)))。其数据结构如下图所示
Read More
2020-06-26
Flink以YarnCluster模式提交任务,且指定任务名和队列
flink run -m yarn-cluster -ynm PROD-fink-data-gather –yarnqueue CClient /home/cclient/danke-flink-data-gather-prod.jar
Read More
2020-06-25
Parallel Execution(并行执行)一个任务被切分成几个并行实例执行,且每个并行实例处理输入任务的一部分数据,并行度会导致乱序问题,任务的并行实力数称为并行性
可以从三个层面限制并行度
Execution Environment Level1env.setParallelism(3);
Client Level1234Client client...
Read More
2020-06-25
watermark(水印) Flink中用于衡量event time进度的机制叫做水印
Read More
2020-06-25
Flink 在 Flink 中需要端到端精准一次处理的位置有三个:
Flink 端到端精准一次处理
Source 端:数据从上一阶段进入到 Flink 时,需要保证消息精准一次消费。
Flink 内部端:这个我们已经了解,利用 Checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性。不了解的小伙伴可以看下我之前的文章:
...
Read More
2020-06-20
问题描述 Presto半夜总是宕机
解决思路 使用arthas分析jvm使用情况
Read More
2020-06-18
先关闭mysql数据库
mv /var/lib/mysql /data/mysql_data
Read More
2020-06-17
编写一个程序,找到两个单链表相交的起始节点。
解题思路 快慢指针
因为两个链表长度可能不一样,但是相交后的元素都是一样的,可以使用快慢指针
***** 分别遍历链表,获取其长度,长链表命名为quickNode,短链表命名为slowNode,二者长度差为quickStep
***** quickNode先运行quickStep步之后,此时两个链表长度相等,用一个循环就能找到相同起始节点
Read More
2020-06-14
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例:
1 2 3 输入:(2 -> 4 -> 3) + (5 -> 6 -> 4) 输出:7 -> 0 -> 8 原因:342 + 465 = 807
Read More